Por Caio César | 14/06/2026 | 8 min.
Nos últimos meses, tenho observado um fenômeno preocupante: a utilização indiscriminada de modelos de IA (“inteligência artificial”, sim, com aspas) para produção de ilustrações fotorrealistas e infográficos. Os resultados, que eu suspeito serem tratados como “bom o suficiente” pela maioria do público-alvo, são deprimentes.
Graças à utilização eticamente irresponsável de novas tecnologias, cujos efeitos e impactos a longo prazo ainda desconhecemos, um punhado de indivíduos pode bombardear redes sociais com imagens mentirosas e exageradas sobre a realidade que se propõem a transformar. O tom, apesar de dramático, é profundamente vazio.
Explicações genéricas e ilustrações exageradas estão substituindo reflexões mais cuidadosas. Visitar e fotografar lugares, ler artigos científicos e redigir textos exercitando pontos de vista minimamente embasados, infelizmente, dá trabalho e não é de graça.
Neste Coletivo, houve o cuidado de formular um protocolo para a utilização de modelos de linguagem. Há algum tempo, quem lê artigos por aqui se depara com uma discreta mensagem indicando o grau de utilização e pode saber mais detalhes, se desejado, contando, inclusive, com uma lista do conteúdo afetado.
Muitas vezes, o conteúdo aqui publicado exigiu horas para ganhar vida, não raramente, em sessões em dias distintos, mas nunca, mesmo no grau mais alto, é produto de um ou mais prompts preguiçosos. Modelos são especialmente úteis para auxiliar nas reflexões, principalmente quando dezenas de fontes externas estão envolvidas, entretanto, não podem ser e não são utilizados como um atalho para uma resposta ou opinião rápida.
Exemplos de utilização razoável de modelos de linguagem, sem reprodução acrítica de trechos ou peças generativas inteiras:
- Revisão legislativa, especialmente útil quando o marco regulatório é denso, caso de planos diretores e zoneamentos;
- Transcrição de conteúdo audiovisual e posterior processamento, extraindo padrões e sínteses;
- Produção de artefatos auxiliares a partir de mecanismos com maior intensidade computacional, com varredura de centenas de fontes, incluindo artigos científicos e textos jornalísticos em periódicos com reputação adequada;
- Revisão textual para minimizar repetição de palavras, frases prontas, falhas na tradução de termos técnicos e vícios de linguagem, a partir do processamento de trechos ou de uma peça inteira escrita por pessoa humana;
- Produção de artefatos visuais complexos, como diagramas e infográficos, desde que subsidiados por conteúdo escrito por pessoa humana.
Não é razoável se propor a discutir problemas como a superlotação dos sistemas de transporte sobre trilhos ou questões complexas envolvendo a forma urbana (morfologia) e a demografia a ela associada com ilustrações genéricas, que não se conectam com nada aprofundado e, consequentemente, não passam de aberrações estocásticas, vomitadas por uma máquina a partir de muito malabarismo estatístico.
Conteúdos vagabundos gerados por inteligência artificial costumam ser tão preguiçosos que apenas uma parte da capacidade do modelo é empregada, seja por imperícia ou incompetência, seja pelo baixo domínio ou desqualificação de quem opera. Quanto mais vagabundo o conteúdo, mais mecânico, repetitivo, raso, dicotômico e previsível ele se parece. Pura estatística.
O padrão atual das empresas que treinam modelos e comercializam tempo de utilização, caso da OpenAI e da Anthropic, é incentivar o uso do modelo de média capacidade e priorizar conversação e agilidade. A configuração padrão é para que o modelo “pense” menos, ou seja, não consuma muitos recursos computacionais com turnos internos que visam melhorar probabilisticamente a assertividade do texto a ser gerado. Além disso, os modelos tendem a ser treinados para não contrariar usuários e toleram uma grande dose de cinismo, desonestidade e hipocrisia.
Em outras palavras, os modelos tendem a amplificar visões distorcidas da realidade. A bajulação não é suspeita minha: as próprias empresas a reconhecem como um possível comportamento defeituoso. E o incentivo econômico empurra na mesma direção: confrontar quem está do outro lado do teclado ou gastar mais computação com um texto aprofundado custa mais e rende menos do que entregar conversa ágil e agradável. Discussões urbanísticas sobre São Paulo passam bem longe de inverdades canônicas como “a Terra é plana”, que geralmente possuem uma maior probabilidade de serem contestadas pelo modelo de linguagem.
Como sei que parte da audiência do Coletivo não é técnica, aproveito para enfatizar que modelos de linguagem não são inteligentes. Eles simulam inteligência, mas não pensam, não possuem agência. A terminologia utilizada pelas empresas induz a erro. Tentando simplificar, modelos de linguagem são máquinas de padrões que funcionam convertendo texto em tokens e estes em imensas matrizes.
Imagine 50 folhas flutuando como uma cascata no espaço. Agora, imagine que cada uma das folhas possui uma matriz muito grande. Finalmente, pense que cada número guardado nessas matrizes é um peso: a força, aprendida no treinamento, com que um elemento influencia o outro.
Pronto, isso é um modelo de linguagem, sendo extremamente simplificador na escala. É um sistema de transformação de matrizes que recebe texto e, a partir de uma rede neural treinada com terabytes de dados, devolve o texto que “deve fazer sentido”. O modelo não sabe o que recebeu, nem o que disse. O modelo apenas recebeu tokens e devolveu tokens a partir de um processo estatístico sofisticado.
Se ainda estiver vago, aqui vai uma ilustração gerada pelo Gemini com auxílio do Claude. Para gerar a ilustração, houve uma discussão prévia com o Gemini, que já conhecia, por contaminação contextual de outras conversas, a predileção estilística a ser adotada, embora esta tenha sido reforçada. Três imagens foram geradas em conjunto com uma crítica em paralelo com Claude, que propôs correções. Só então a imagem abaixo, mais precisa, mas ainda permeada por algumas simplificações, foi gerada.
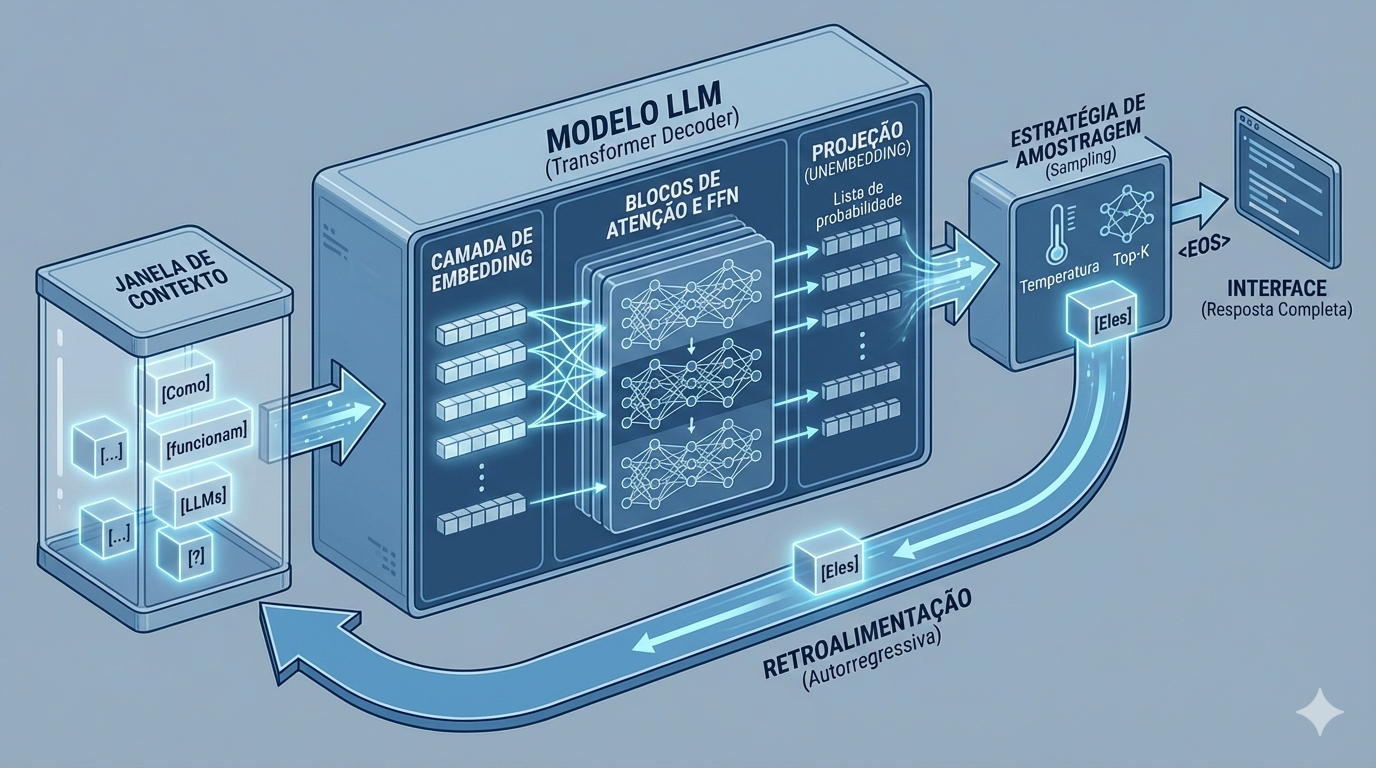
Não foi imediato, havia conhecimento prévio pelo operador (no caso, euzinho) e até o estilo da arte foi imposto, também exigindo referências (predileção por perspectivas isométricas, apreciação de infográficos em revistas densas de informática das décadas de 1980 e 1990, contato de longa data com computadores, hábitos de leitura e escrita de longa data).
E, antes de inserir a ilustração neste artigo, eu utilizei o modelo mais poderoso ao qual tenho acesso, Claude Opus 4.8, com nível elevado de esforço e escrutínio sobre o processo de “pensamento”. O Opus, diante do prompt “O que acha dessa ilustração sobre o funcionamento de LLMs?” numa conversa privada, apontou, entre outras coisas, o seguinte:
A "lista de probabilidade" na verdade são logits convertidos por softmax, e cobrem o vocabulário inteiro (dezenas de milhares de tokens), não uma listinha curta. Detalhe menor, mas a escala real é muito maior do que a figura sugere.
Eu não acho que o tipo de ilustração vagabunda que tem aparecido tem 10% desse cuidado. E, pelo fragmento da resposta acima, há uma sutileza: o próprio modelo, como deveria ser intuitivo pela explicação que eu estou dando, subiu a régua. Um diagrama sobre algo sofisticado foi submetido e o texto gerado tem traços que pressupõem conhecimento não trivial, daí a menção a logits e softmax.
E eis aí a ironia do destino: como eu utilizei o Claude para fazer uma simples consulta em torno de algo feito no passado, o mínimo que eu posso fazer para ser honesto é classificar este texto como tendo nível 2 de utilização de IA, pois reproduzi um pequeno bloco acima. Honestidade e processo.
Acho que não é preciso muito esforço para suspeitar que, se fosse desejado, toda a abordagem poderia ser melhor, mesmo que altamente dependente de um modelo de linguagem, simplesmente porque o modelo é como uma calculadora difícil de parar. O freio é quem pressiona os botões.
Alguns maus exemplos:
- ViaMobilidade Linhas 5 e 17 utiliza IA e distorce salão de passageiros de um trem da frota P;
- Perfil originalmente criado para defender o Parque Augusta tem feito uma série de cartazes que sugerem o uso de IA, num deles, o emprego de modelos parece presente no texto e nas imagens dramáticas, que substituem e esvaziam exemplos da vida real;
- Denúncia de deterioração das linhas de metrô feita pelo mandato da vereadora Marina Bragante parece ter utilizado IA de forma preguiçosa, inclusive, nas respostas (o mandato ainda falha em oferecer medidas críveis quando nós questionamos);
- O caso do teatro que teve a “demolição antecipada no passado”, com uma imagem gerada a partir da fachada antiga alimentando críticas hipócritas;
- Outra dramatização tosca feita em abril envolvendo Pinheiros, com frases afiadas que parecem saídas do ChatGPT, isso se a imagem em escala de cinza também não saiu;
- Denúncia legítima de aparente perda de capacidade com eletrificação dos ônibus se perde em meio ao rodoviarismo e a um quadrinho que, como outros materiais que parecem gerados preguiçosamente por IA, é dicotômico demais e insere elementos genéricos demais (como um micro-ônibus escolar no lugar de um ônibus verde alimentado por baterias);
- Governador Tarcísio parece ter utilizado IA para fazer propaganda em torno da região do Moinho e tudo parece errado: o fluxo de veículos distorcido, os trens omitidos, as vias que desaparecem e a aparente desconexão entre as diferentes perspectivas conforme a escala muda.
Espero que mais pessoas entendam que precisamos de conexões verdadeiras com os lugares que queremos transformar e os problemas que queremos resolver.
Substituir a paisagem por uma aproximação grosseira e terceirizar a elaboração de textos curtos, como os textos de até mil caracteres do Instagram, não faz o menor sentido. Como esperar que a realidade mude fugindo dela? Como esperar mobilizar outros quando o desinteresse já começa na elaboração da mensagem?
Muitos dos artigos publicados por mim utilizaram o Trem Metropolitano como fio condutor. Inúmeras vezes, eu considerei que estava numa posição marginal e que falava de porções do território que eram ignoradas ou invisibilizadas. Nunca forjei indignação ou sofrimento. Estive presente nos lugares e nas linhas. Eu não preciso de mais conteúdo de má qualidade, com trens distorcidos e paisagens chutadas: eu preciso de gente genuinamente interessada em mudar o futuro.
Se você ainda não acompanha o COMMU, curta agora mesmo nossa página no Facebook e siga nossa conta no Instagram. Veja também como ajudar o Coletivo voluntariamente.
comments powered by Disqus